Created by Kamila Klavíková
A mix of notes from various lectures. Created as preparation for the final exams. Translated from „DNA, mutace, mutageny a opravy poškozené DNA“ (https://orgpad.com/o/DWDGlWlTVDAL__dTjVW77H?token=ABwWD9tOVGX5anyPht2sbF)
Submicroscopic obligate cellular parasites. They do not have their own energy metabolism, do not grow, are formed by the fusion of individual components. They can only divide within the cell.
A virus particle is called a virion. Minimum equipment of virion - hereditary information (RNA/DNA) and viral capsid (NK protein coat). In addition, the virus may contain an additional envelope around the capsid and various enzymes and proteins.
Viral genomes are small and complex. The genome is often folded by viral histones and associated with capsid proteins. The genome must be readable by the replication and transcription-translation apparatus of the cell.
The capsid is physically and chemically resistant. NK also encodes other necessary proteins.
All possible variations of replication modes (dsDNA, ssDNA, dsRNA, (+)(-)ssRNA).
mobile genetic elements, transposons, dispersed repeats
Transposable elements are fragments of DNA able to change their position / move within the genome of one organism (in broader def. also between organisms). They are dispersed repetitive sequences.
They occur in archaea, bacteria, eukaryotes and viruses (Pandoraviruses).
Transposons often spread horizontally. In evolution, periods when TEs are active and proliferate alternate with periods of quiescence.
As a rule, only small amounts of intact whole transposons are found in the genome. The majority are non-functional, truncated or otherwise damaged transposon sequences. But even damaged ones can be copied if there are at least a few undamaged copies in the genome that supply the necessary enzymes. Transposons can make up a significant proportion of the genome (1000 to 10,000 copies, human 50%, orca 98%) .
Discovery of transposable elements on Ac/Ds elements of maize kernels (activator - autonomous, dissociator - non-autonomous).
X-rays, γ-rays and cosmic rays...
Ionizing radiation induces structural changes in chromosomes due to bichromatid breaks. It penetrates tissues at various distances. It is used in clinical practice.
UV radiation causes the formation of thymine dimers (TC, CC dimers can also be formed) and cytosine hydrate. It penetrates tissues only through the cell surface layer. It is readily absorbed by organic molecules. It does not cause ionisation. Leads to the excitation of electrons to a higher energy level, thus causing higher reactivity of molecules.
It repairs almost any damage, e.g. due to DNA-based carcnogen binding or pyrimidine dimer.
The DNA is scanned looking for helix distortion, not a change in primary structure (at individual bases).
In E. coli 4 Uvr (UV repair?) proteins responsible for this system. UvrA*UvrB scan the DNA, UvrA is responsible for detection, once detected UvrB unwinds the DNA at the site of the distortion. UvrC (endonuclease) then cleaves 8 nucleotides from the lesion on the 5' side, 4-5 nucleotides from the lesion on the 3' side. UvrD (helicase) removes the damaged section. The gap is filled with DNA polymerase and sealed with DNA ligase.
In eukaryotes up to 25 proteins - XP genes, mutation of these leads to increased sensitivity to UV → Xeroderma pigmentosum disease. Transcription-coupled DNA repair - if RNA polymerase latches onto a DNA error, repair proteins come in and repair the damage → RNA polymerase can act as a DNA damage sensor.
Photolyase repairs pyrimidine dimers. Removal of methylation by methyltransferase.
Mutations are changes in the structure of genetic material that alter the meaning of genetic information without breaking the syntactic rules of its notation. We refer to changes in the DNA sequence as mutations.
A distinction should be made between mutations that respect the rules of DNA writing and DNA damage. Mutations are the greatest source of genetic variability.
Gene mutations. They affect only one gene.
Chromosomal mutations. Change in chromosome structure, gene order, position of centromeres.
Genomic mutations. Total genome change (polyploidization, aneuploidization).
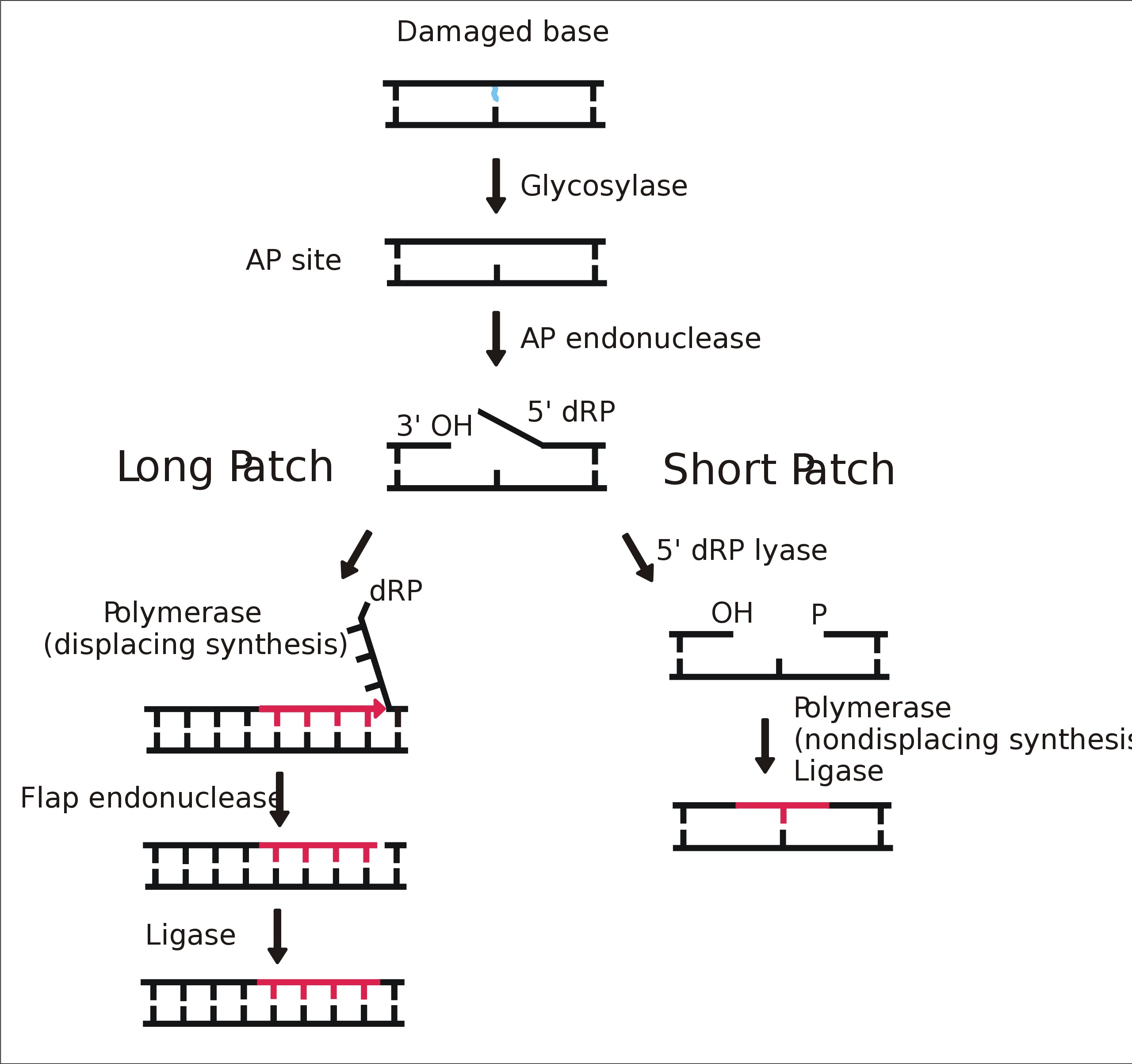
Repair according to the intact strand (dependence of excision repair on the ds nature of the nucleic acid). 3 general steps:
Photoreactivation. The enzyme DNA photolyase repairs pyrimidine dimers after illuminating DNA with UV light. It uses the energy of visible light.
Demethylation. Methyltransferase transfers the methyl group from 6-O-methylguanine to cysteine, very energy intensive.
Some of the mispaired bases are repaired by DNA polymerase - the palm domain checks the pairing of the currently attached nucleotide, if it detects an error, the primer*template complex is released from the polymerization site (thumb and finger) and goes to the repair site on the palm domain, where the 3'→5' exonuclease activity of the palm domain kicks in.
Mismatch repair system repairs misclassified nucleotides during replication. It corrects errors not corrected by DNA polymerase.
The system needs to recognize which base to replace in a mispairing, it needs to know which strand served as template in the replication that took place.
In gram-negative bacteria, the template strand is methylated, the new strand is not yet. In other prokaryotes and eukaryotes, the mechanism is not clear; in eukaryotes, the non-templated filament is probably distinguished by the presence of nicks. These also appear in the leading filament. Whether they are artificially introduced there is not clear. Proteins in E. coli- MutS, MutL, MutH, PCNA clamp protein
linear polymer, double helix of mutually antiparallel strands. This structure allows a semiconservative mechanism of replication. Stability of the double helix ensured by hydrogen bridges, stacking interactions.
Stacking interactions are formed by the fusion of regions of occurrence of delocalized π electrons of aromatic rings of adjacent bases, the polarity of phosphate groups.
One of the remarkable features of DNA is its ability to undergo reversible strand separation, known as denaturation, and renaturation. This characteristic also allows for the possibility of hybridization, where two complementary strands from different sources, such as RNA and DNA, can join together. How readily DNA denatures depends on GC content (more GC → less willingness to denature – 3 hydrogen bonds between G and C vs. 2 between A and T).
Base analogues are incorporated into DNA during replication.
E.g. 5-bromouracil (analogue T), 2-aminopurine (analogue A).
Hydroxylating agents e.g. hydroxylamine converts cytosine to hydroxylamincytosine.
Intercalating agents are incorporated or wedged into DNA, causing frameshift mutations.
Ex: ethidium bromide, acridine orange, proflavine.
ROS (reactive oxygen species) are reactive oxygen species that damage DNA, lipids and proteins. Their production occurs in the mitochondria. About 2-3% of the oxygen in mitochondria is reduced to ROS.
They are removed by superoxide dismutase (superoxide radical → H2O2), catalase (H2O2 → H2O), glutathione peroxidase.
There is not always a correlation between metabolic rate and lifespan (faster metabolism...- shorter life). There are a number of exceptions such as birds, marsupials, bats... Although the body of the naked-mole rat is subjected to high levels of oxidative stress, it lives to 28 years in captivity. So it must have different mechanisms.
Ex: peroxides, superoxides, hydroxyl radical, singlet oxygen.
Alkylating agents add an alkyl group, causing substitutions (transversions and transitions) and chromosome aberrations.
E.g. EMS, MMS ⇒ alkylation of G at position 6 ⇒ pairing with T ⇒ changing GC to AT
Nitric acid replaces the amino group with a keto group, this process is called oxidative deamination. It acts on A, C, G.
Změna exprese, NE produktu; down mutace → snížení transkripce + zvětšení vzdálenosti od START nukleotidu; up mutace → zvýšení transkripce; zmenšení vzdálenosti od START nukleotidu.
Mutation of an allele of a certain gene in a somatic cell that already carries a mutated allele of the same gene on the homologous chromosome.
They do not concern DNA; mostly during transcription; the expression usually weakens over time.
Mutace v 3´sestřihovém místě → sestřihový aparát toto místo přeskočí a dojde k odstranění exonu z transkriptu
Mutace v 5´sestřihovém místě → zachován intron v transkriptu
Ve stejném místě jako byla mutace přímá.
Pravá reverze. Obnova mutované skevence nukleotidů na původní. Opačná reverze – změna kodonu na kodon synonymní k původnímu kodónu (před pímou mutací).
Částečná reverze. Změna kodónu na nesynonymní kodón, leč takový, že dojde k úplné či častečné obnově funkce s novou AK oproti mutaci přímé.
Effect on the expression of one adjacent gene; genes located on one side of the mutant gene."
Regulatory mutations are changes in a gene that alter the expression of other genes by affecting the transcriptional activity of those genes.
Supresorová mutace. Maskuje účinek přímé mutace; intragenová (mutace v témže genu, ale na jiném místě) X intergenová (mutace v jiném genu než přímá mutace)
Enhancerová mutace. Opak supresorové; zvýšení intenzity mutačního fenotypu; často letalita.
Buněčný typ: somatické buňky / buňky zárodečné linie
Typ chromozomu: autozomální / gonozomální
Molekulární změna: substituce / inzerce / delece
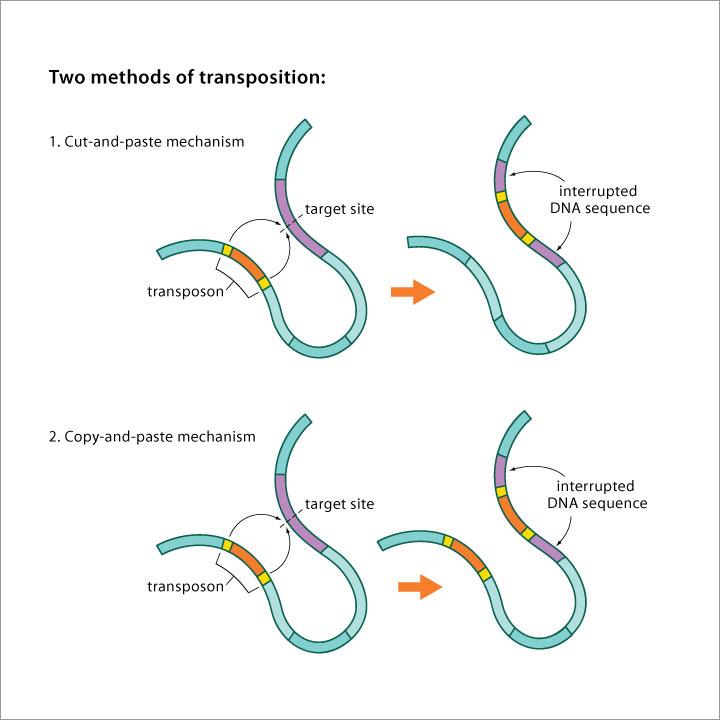
Carry information necessary for their own movement (genes encoding enzymes that allow transposition).
Inability to move without the participation of autonomous elements. However, they can transfer them. Usually autonomous elements that have lost the gene(s) (or have damaged gene(s)) for the enzyme that allows transposition.
Dominant. If expressed late in ontogenesis, transmission to the next generation.
Recessive. In the population, mainly preserved in heterozygotes. Unusual segregation ratios in the offspring of the F2 generation.
Auxotrophic. Inability to synthesize a certain important nutrient.
Temperature sensitive. Product unstable at certain temperatures.
Viability only in the presence of a suppressor.
Loss-of-function mutation. Reduced function (= leaky mutation) + loss of function (= null mutation) of the mutated gene.
Gain-of-function mutation. Increased function; greater amount of product; gain of new property.
Induced mutations are caused by mutagens, which are substances, environmental factors that induce mutations. They are of different nature, biological, physical and chemical.
They use reverse transcriptase for transposition. Copy-and-paste via RNA intermediate. They represent a significant part of the genome (42% in humans / while DNA transposons only 2-4%).
LTR retrotransposons. They have LTRs (long terminal repeats) at their ends. Very common in plants, rarer in animals. Similar to retroviruses. Probably evolved from retroviruses. They are remnants of ancient viral infections.
PLE retrotransposons. PLEs (penelope-like elements) have LTRs at the ends (can be inverted), form TSD(target site duplication) - short direct repeat. They encode an endonuclease.
Ends in an AT-rich region.
LINES (long interspersed nuclear elements). Up to several kbp in length. Very common in animals, rarer in plants.
SINES (short interspersed nuclear elements). Non-viral non-autonomous retrotransposons. They do not encode reverse transcriptase. They use reverse transcriptase of other elements (mostly LINES) for transposition. They form TSDs. AT-rich sequence of 100-500 bp at one end.
Somatické mutace. Projev u potomků somatické buňky; nepřenáší se gametami do potomstva; ztráta heterozygozity = mutace alely genu v somatické buňce, která už nese na homologickém CH mutovatou alelu téhož genu (retinoblastoma u člověka); dominantní mutace se projeví ve fenotypu
Gametické mutace. Přenos gametami do potomstva; dominantí mutace projev ve fenotypu potomstva
Bodové mutace. Záměna dvou nukleotidů (inzerce, delece, transverze – různý typ báze, tranzice – stejný typ báze)
Řetězcové mutace. Záměna celého úseku DNA (duplikace, inzerce = zmnožení řetězce DNA, delece = vystřihnutí úseku DNA, translokace = vzájemné vyměnéní úseku DNA, inverze = určitý úsek DNA je z chromozomu vystřihnut a vložen do stejného místa v opačné orientaci – může způsobit reprodukční bariéru a tím speciaci)
Chromozomální mutace. Translokace velkého rozsahu vznikající při mitóze. Následky drastické – mládě se ani nenarodí, nebo nemoci typu Downův syndrom.
Genomové mutace. Probíhají na úrovni chromozomů či chromozomových sad v důsledkem poruch v průběhu buněčného dělení (aneuploidie, polyploidie, autopolyploidizace, aloploidizace)
Reorganization of DNA due to recombination between 2 copies of a transposable element. Deletions, inversions occur. Depends on whether the copies are direct or inverted. Genome enlargement occurs.
Depends on the insertion site. Possible effect even after excision of an element in cut-and-paste transposition. Transposable elements have an evolutionarily acquired tendency to insert into safe heavens, non-coding parts of genomes where their insertion does not damage the host.
Some neutral mutations are weakly negative. In a huge population, they would behave negatively.
They do not use reverse transcriptase for transposition. They are flanked by reverse repeats.
Cut-and-paste transposition. Transposition produces double-strand breaks.
TIR elements. They have inverted repeats (TIR) at the ends. Transposition by transposase.
Ac/Ds elements in maize.
P elements. The most important elements in Drosophila. They are encoded by alternative splicing - either transposase or repressor protein.
Copy-and-paste transposition, but not via an RNA intermediate. Transposition produces single-strand breaks (cointegrate formation).
Helitron elements. They do not have a TIR at the ends and do not form a TSD. Especially in plants.
Maverick elements. TIR at the ends. They are large (up to 20 kbp). Not detected in plants. Specific mechanism of transposition.
changes in meaning (effect on translation)
Synonymous mutations. A substitution in one base that does not change the encoded AA.
Missense mutation. With a missense. Changing the codon for one AA for the codon for another AA.
Nonsense mutation. A nonsense substitution resulting in a stop codon in place of the codon for an AA.
Spontaneous mutations occur naturally without a known cause.
In deamination, an amino group (-NH2) is replaced by a keto group.
Cytosine. Hydrolysis to uracil.
5-methyl-cytosine. Hydralysis to thymine. Site of the most common mutations in vertebrates.
Adenine. Produces hypoxanthine, which binds preferentially to cytosine. So essentially a GC pair is formed.
Guanine. Xanthine is formed, which pairs with thymine. The new pair is essentially AT.
Loss of purine/pyrimidine base and formation of an apurinic/apyrimidine site (AP site).
Ex: loss of purine base (A, G) ⇐ breaking of glycosidic bond between deoxyribose and purine
Slippage is the slipping of DNA polymerase during replication, local denaturation, and subsequent repair. Forward slippage - deletion, reverse slippage - addition. It can occur anywhere in the DNA. Most often it occurs in repetitive sequences.
A base is altered by changing the position of a hydrogen atom. The way the hydrogen bridges are formed is altered, changing the pairing. Stable forms of bases - keto (G, T) and amino (A, C), less stable enol and imino.
From plasmid to plasmid, or from plasmid to bacterial chromosome.
The number of mutations at a given position per unit time of all members of the population.
The incidence of a given mutation is expressed as the proportion of mutant individuals in the population. Higher mutation frequency in males (higher selection pressure on the X chromosome and higher number of cell divisions during spermatogenesis).
Classical Darwinism is based on the gradual accumulation of micromutations, i.e. mutations that cause small changes from the original state.
However, there are also macromutations that cause a significant change in the structure or functioning of the body (a third arm, one leg...). However, it is questionable whether some major new organs such as wings etc. could arise in this way. Macromutations exist, but their role in evolution is uncertain. It is only through macromutations that interspecies differences can arise.
The idea of the possibility of transitioning from one species to another by switching alternative ontogenetic programs. E.g. when wheat is not doing well, it starts to change to rye, which would do better under the given conditions.
This idea is not entirely reprehensible, but in the context of the whole lysenkoism (falsification, ideology) it is out of place.
Mutation sites are not evenly distributed in the DNA strand - they are more likely to occur at hot spots. Changes in mutation frequency are also observed over time, with significantly more mutations occurring at certain points in evolution - it is not fully understood why - sequence motif (AT sequence motifs), external conditions, sex differences (males mutate more often)... There are also places where more mutations do not arise, but where mutations are more easily fixed.
Some organisms can start mutating faster under stressful conditions, increasing their chances of survival. Some authors believe that they not only mutate faster, but do so purposefully, e.g. Trypanosoma can produce many different variants of surface proteins and does so deliberately at certain times and under certain conditions.
It varies between the sexes. Males mutate more often - they can try evolutionary novelties when they produce sperm. Females are more conservative, have fewer of them, and it wouldn't be worth the risk.
Role of mutators - pathogenic bacteria have many mutators in the population, so they try to find optimal virulence.
error prone repair
trans-lesion DNA synthesis: when DNA polymerase encounters an unrepaired error, it dissociates with the clamp protein. Translesion DNA polymerase takes its place and bridges the damage site, but generates errors (it is not as dependent on base pairing).
But the existence of targeted mutations alone would not be sufficient for Lamarckian evolution. The vast majority of mutations are random.
The first obstacle to Lamarckian evolution is the lack of backflow from proteins to DNA.
The second obstacle is the Weisman barrier between the germline and the somatic lineage.
The third obstacle is the fact that genetic information is not an accurate description of structure.
One of the trends denying Darwinism is mutationism. Its proponents have argued that the most important source of mutations are reparative processes. However, they were unable to explain the evolution of adaptive traits. This is explained by the mechanism of natural selection, which is indispensable for the spread of advantageous mutations.
Repair of double-strand breaks (caused by ionizing radiation, due to oxidizing agents), when nucleotides are lost between the strands of the break.
They are defined due to the N-glycosidic bond. They intersect. They are determined by the span of the ribose-phosphate groups. All types of base pairs (A-T, T-A, C-G, G-C) can be distinguished in the major groove.
for purine, on the side where N3 and C4 are; for pyrimidine, C2
the whole other side, there are many more substituents in the large groove - these are recognized by regulatory proteins that bind to the DNA in the large groove region
In the small the difference between (A-T + T-A) and (G-C + C-G). DNA binding proteins therefore distinguish DNA sequences preferentially in the large groove. Distinction by the presence of the following groups protruding from the base pair into the groove: A - hydrogen bond acceptor (hydrogen), D - hydrogen bond donor (hydrogen), M - hydrophobic methyl group, H - non-polar hydrogen. The dimensions of the groove may show local variations, bases may be helically twisted → DNA is not a perfect helix.
Telomerase in eukaryotes. When replication is terminated, the last nuclease-removed RNA primers cannot be replenished; telomerase does not need template and functions by a reverse transcriptase mechanism; mounts on a 3' overhang and extends the end; solves telomere end problems and prevents telomere shortening during replication.
Topoisomerases are enzymes that change the topology of DNA. They remove the positive supercoils that form upstream of the replication fork. RNA primers are replaced by DNA polymerase I at the end of replication and nicks are ligated by DNA ligase.
Type I produces an ssDNA break (nick). They store energy in the form of phosphotyrosine (the phosphate from the nucleotide binds to tyrosine on one side). The reaction is reversible (the phosphate spontaneously binds back to the nucleotide after a period of time). Thus, the reaction does not need an energy supply in the form of ATP.
Type II produces a dsDNA break. They are activated by ATP binding and dimerization at chromosome crossing sites. They create a break in one DNA strand, stretch the other DNA strand and close the break. Hydrolysis of ATP then returns them to their original state where they can locate other crossing strands. Topoisomerase IIs are able to, amongst other things, separate stranded cccDNA (essential in prokaryotic replication).
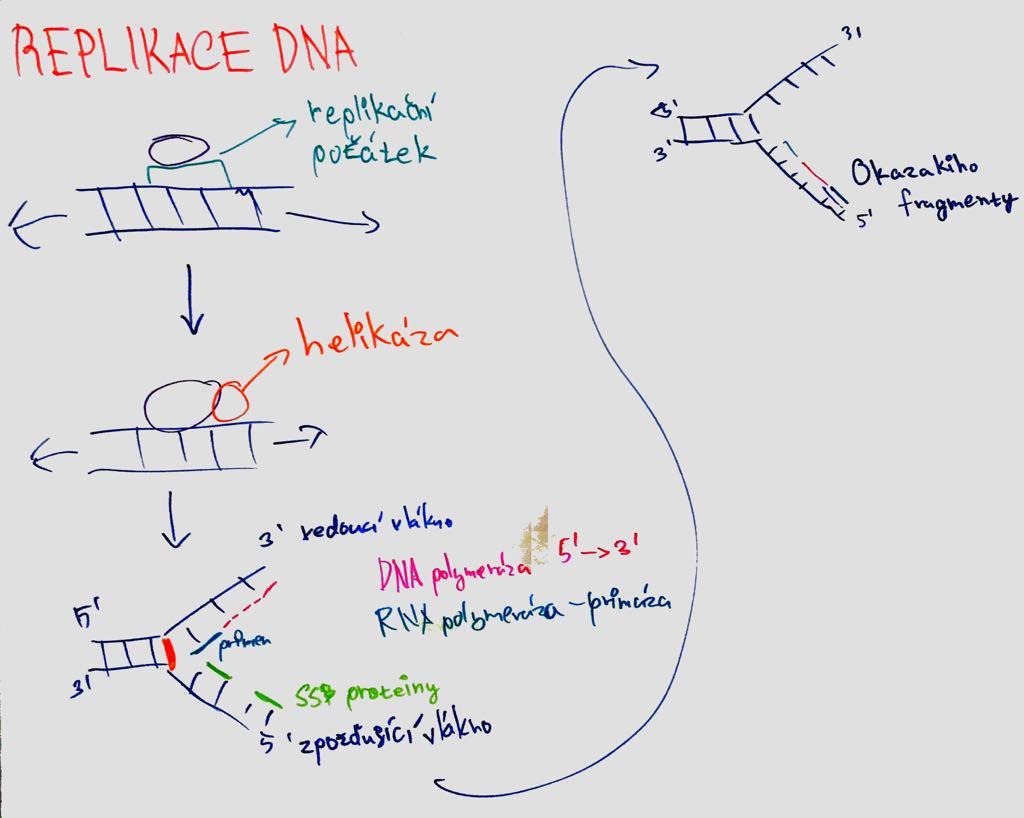
semiconservative = new molecule from 1 old and 1 new strand; both chains are complementary and can serve as template.
replication apparatus = set of proteins for replication;
replication origins = ori = sites where the double helix breaks first (these sites are recognized by initiation proteins; rich in AT; in bacteria the genome is circular and thus 1 origin);
replication fork = Y-shaped replication origins where repl proteins bind. Apparatus (move in direction of replication and unwind helix to synthesize new filament; two form in 1 ori and move apart);
DNA polymerase = enzyme that catalyzes DNA strand polymerization - inserts deoxyribonucleotides and elongates the strand (hand shape; palm domain controls pairing; finger domain closes dNTP at catalytic site; thumb domain holds synthesized DNA; catalyzes attachment of nucleotides to 3'end; Mg ions in the active site; NTP provides energy; has repair function = proofreading - checks previous pair before adding nucleotide); synthesis in 5´- 3´ direction; leading strand = leading strand (synthesis continuous) X lagging = lagging strand (discontinuous;
Okazaki fragments = primers - nuclease removes RNA primers, DNA Pol replaces them and ligase joins them));
primers = short stretches of RNA (DNA POL cannot start synthesis on its own; formation by primase);
helicase = unfolds ATP while consuming ATP; SSB proteins = protect single-stranded DNA from splicing;
sliding clamp proteins = clamp (bind DNA POL to template); replisome (complex of proteins involved in replication at the fork site)
Important - when the helicase develops DNA, supercoiling occurs in front of it. Type I topoisomerase will cleave one strand of DNA, allowing it to turn towards the other strand and remove the supercoil.
Nucleoside. Base + sugar (adenosine, guanosine, thymidine, uridine, cytidine).
Nucleotide. Forms the primary structure. It is a combination of nucleoside and phosphoric acid (ATP. cAMP, GDP...)
Bases linked via a (deoxy)ribose phosphate skeleton. Polarity according to the 5' and 3' end of ribose. Bases can tautomerize – adenine and cytosine to iminoform, guanine, thymine and uracil to enolform.
DNA and RNA (deoxyribonucleic acid and ribonucleic acid).
The only difference between them is ribose.
circular DNA molecule; 1 ORI;
a) replication forks in both directions and mounts on DnaA protein - DnaB helicase unwinds helix - primase synthesizes primer - DNA POL III elongates chain; primosome = helicase-primase complex moves around DNA; DNA POL III elongates primers - DNA POL I exchanges RNA for DNA - ligase links them together; termination of replication in terA and terB;
(b) rolling circle; single strand breaks circular molecule - second intact strand replicates - formation of product where copies of plasmid are placed behind each other - cut to correct size and ligated
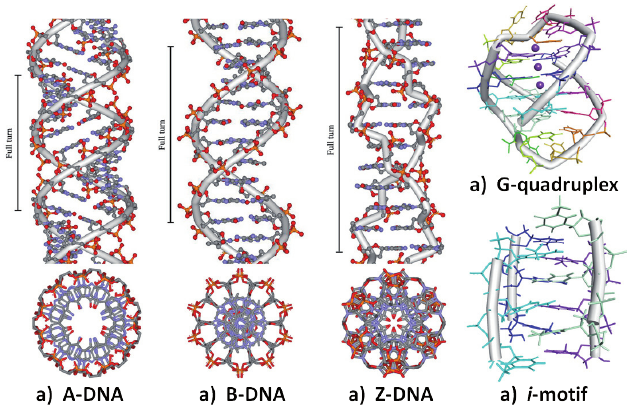
A conformation. 11 bp per strand. Right-handed. Short and strong. Large groove deep and narrow. Small groove wide and shallow.
B conformation. 10 bp per strand. Right-handed. Long and thin. Large groove wide (> 180°). Small groove narrow (< 180°). DNA is predominantly found in this conformation.
Z conformation. 12 bp per strand. Left-handed. Elongated zigzag structure. antiC, synG glycosidic linkages. Only one groove. The second structure is not a groove, just the outer surface. Occurs mainly where purine and pyrimidine alternate. As a rule, these are GC-rich regions.
The N-glycosidic bond between the base and deoxyribose has the possibility of rotation, therefore syn and anti position of the base relative to the ribose is possible. The N-glycosidic bond is the bond formed between the nitrogen of the base and the C1' carbon of ribose.
It is described by torsion angles c involving the O4'-C1'-N1-C2 atoms of pyrimidines and O4'-C1'-N9-C4 atoms of purines.
~ 0° (+/- 30°) = syn = cis
~ 180° (+/- 30°) = anti = trans
Note: syn conformations can be artificially induced e.g. by bromination
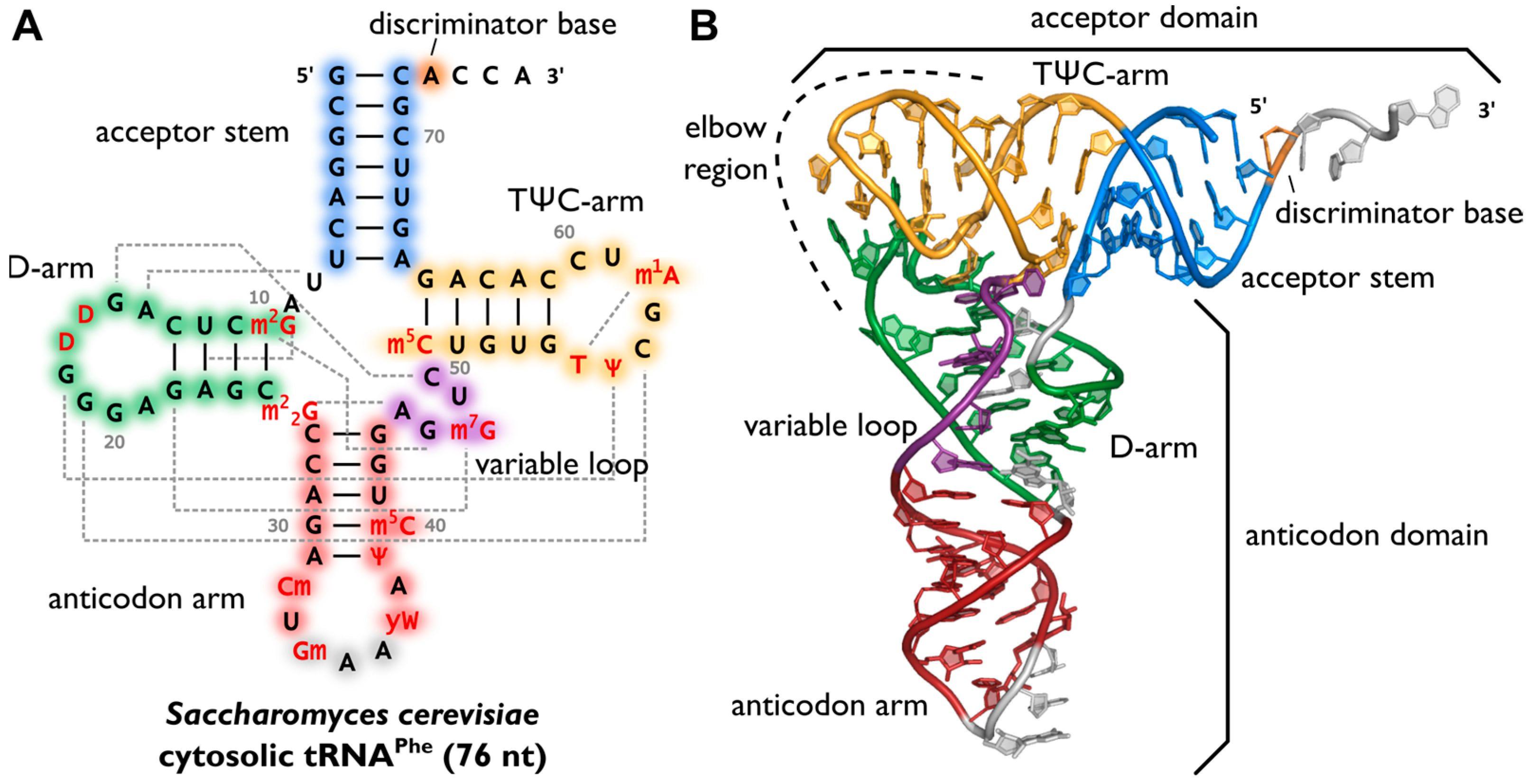
75 - 95 nucleotides, contains several non-standard bases. Secondary structure of cloverleaf. 4 arms:
Acceptor arm - includes both 5' and 3' end, at the 3' end an amino acid binds via an OH group attached to the C2' or C3'ribose of the last nucleotide (adenylate in the CCA sequence)
Pseudouridine arm (TψC) forms a loop containing a pseudouridine
Dihydrouridine arm (DHU) forms a loop containing dihydrouridine
Anticodon arm forms a loop in which an anticodon-triplet complementary to a codon on the mRNA is localized
Hydrogen bonding of tRNA ribonucleotides, particularly on the dihydrouridine arm, also leads to the formation of the tRNA tertiary structure, important in proteosynthesis.
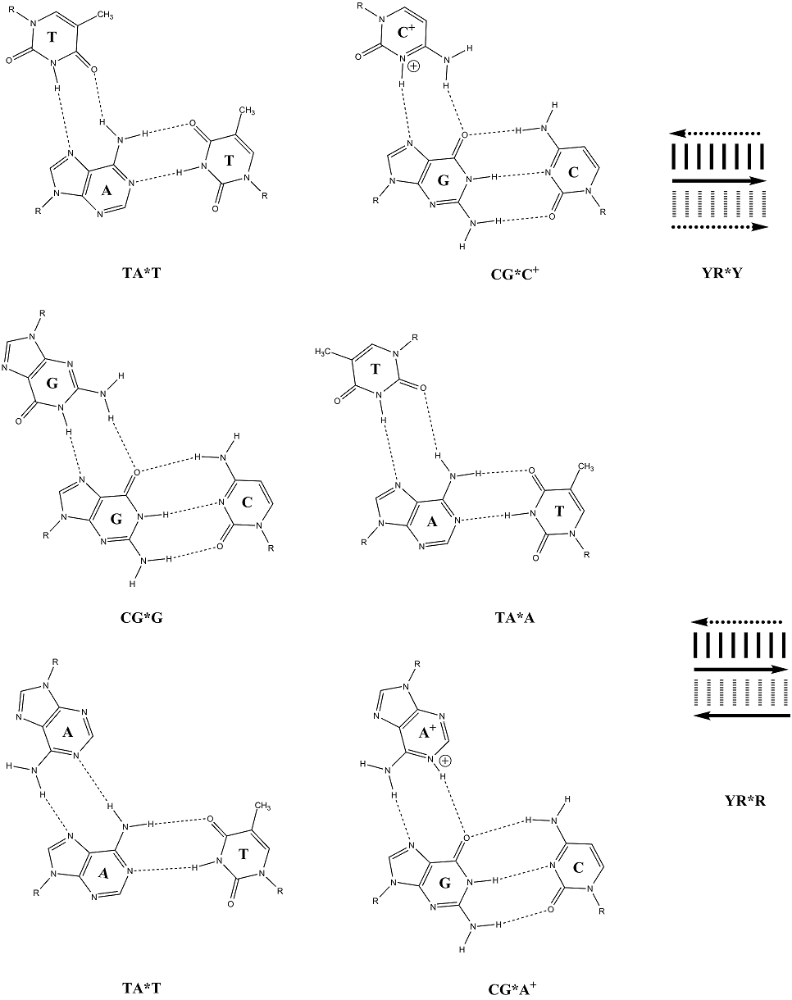
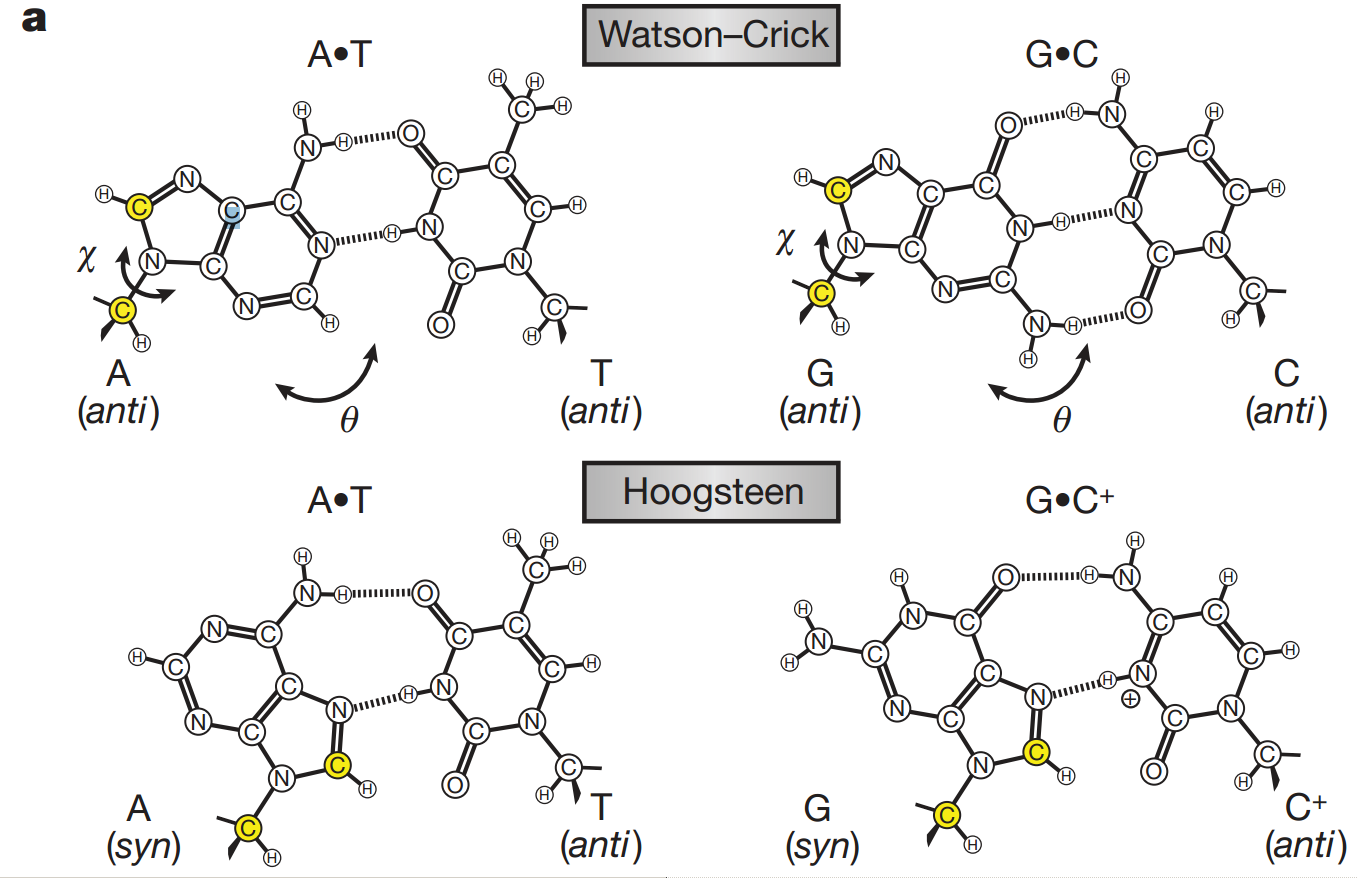
Bases can form hydrogen bonds with more than one partner → H DNA triplex, G quadruplex (G-quartet).
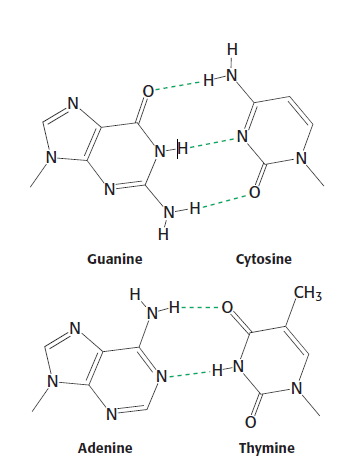
Two nucleic acid strands interact with each other by complementary pairing using hydrogen bridges.
There is always one purine and one pyrimidine in the pair. The pairing provides a certain symmetry. The C1' carbons are approximately equidistant in both cases.
Pairs adenine with thymine (2 H-bridges) and guanine with cytosine (3 H-bridges).
Non-standard pairing of anticodons to codons - U at position 1 of the tRNA anticodon can read both A and G at position 3 of the codon, G at position 3 of the anticodon can read both U and C at position 1 of the codon, inosine reads C, U, A.